Prüfen in Zeiten von KI
Traditionelle Prüfungsformate funktionieren nicht mehr. Vier Strategien, um weiterhin wirksam zu prüfen.
Artikel lesenWer KI-generierte Texte bewerten will, sollte verstehen, wie sie zustande kommen. Sprachmodelle verfügen nicht über Wissen im menschlichen Sinne. Sie verfügen über statistische Muster, die sie aus Texten extrahiert haben. Dass dabei etwas entsteht, das wie Wissen wirkt, kann leicht zu einem unangemessenen Vertrauen gegenüber KI-Output führen. In jedem Fall ist es wichtig, sich damit auseinanderzusetzen, was in KI-Antworten mitfließt, wenn man regelmäßig mit Chatbots arbeitet.
Das "Wissen" eines KI-Chatbots stammt aus drei Quellen, die aufeinander aufbauen: einem Grundtraining auf riesigen Textmengen, einer Feinabstimmung durch menschliches Feedback sowie ggf. einer Recherche in externen Quellen zum Zeitpunkt der Nutzung. Jede dieser Stufen schärft den KI-Output, führt zugleich aber auch zu spezifischen Verzerrungen und Fehlerquellen.
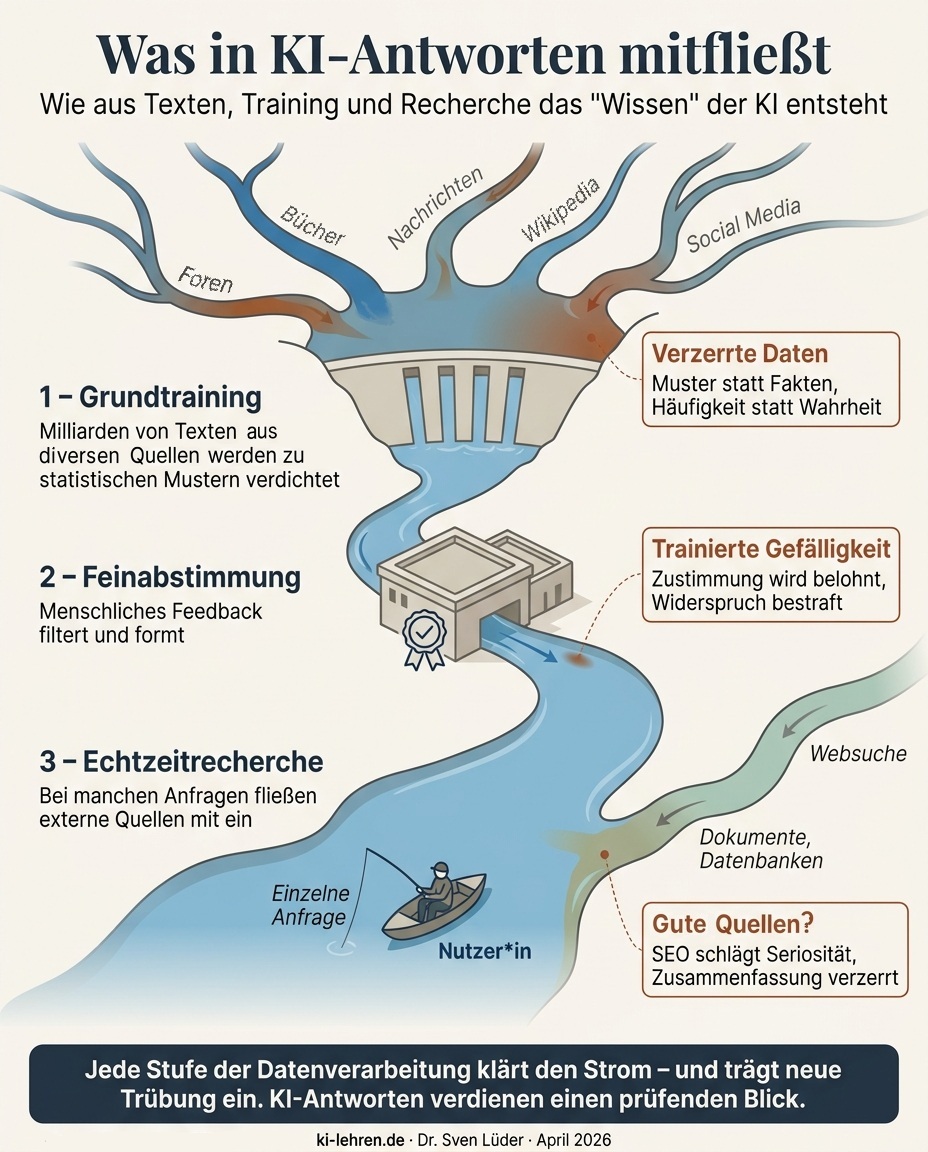
Im sogenannten Pre-Training (das "P" in ChatGPT steht für "Pre-Trained") wird das Sprachmodell auf Milliarden von Texten trainiert. Das Verfahren ist überraschend simpel: Das Modell lernt, das jeweils nächste Wort in einem Satz vorherzusagen. Es braucht dafür keinen Lehrer, der ihm sagt, was richtig oder falsch ist – der Text selbst liefert den Maßstab. Aus dieser einfachen Aufgabe, milliardenfach wiederholt, entsteht die Fähigkeit, flüssige und oft inhaltlich plausible Texte zu erzeugen. Was dabei nicht entsteht, ist Verständnis. Das Modell hat nach dem Training kein inneres Modell der Welt und keine Fähigkeit zur Überprüfung seiner Aussagen. Es hat Muster gelernt, die in den Trainingsdaten dominant waren: welche Wörter in welchen Kontexten aufeinander folgen.
Damit sind zwei Fehlerquellen angelegt. Erstens: Die Trainingsdaten (Bücher, Wikipedia, Nachrichtenartikel, Forenbeiträge, Social-Media-Posts etc.) spiegeln die Welt nicht neutral wider. Der Philosoph Roberto Simanowski geht in seinem Buch "Sprachmaschinen" ausführlich auf diesen Aspekt ein. Englischsprachige, westliche, männliche Perspektiven sind überrepräsentiert. Fehlinformationen, die im Netz kursieren, fließen ebenso ein wie gesellschaftliche Vorurteile. Das Modell übernimmt diese Verzerrungen, weil es nicht zwischen wahr und falsch unterscheiden kann; es kennt nur häufig und selten. Zweitens: Bei Fakten, die in den Trainingsdaten selten oder widersprüchlich vorkommen, gerät das Modell ins Raten. Ein Forschungspapier von OpenAI (Kalai et al., 2025) zeigt, warum das systematisch passiert: Das Trainingsziel, also die Vorhersage des nächsten Wortes, belohnt nämlich plausible Fortsetzungen, nicht korrekte. Wenn das Modell nach dem Geburtstag einer wenig bekannten Person gefragt wird, ist es statistisch günstiger, ein plausibles Datum zu nennen, als zuzugeben, dass man es nicht weiß. Halluzinationen sind daher kein Bug, sondern eine Struktureigenschaft des Verfahrens.
Nach dem Grundtraining ist das Modell ein leistungsfähiger Textfortsetzungsautomat, aber noch kein brauchbarer Gesprächspartner. Auf die Frage: "Wie macht man eine Pizza?" antwortet es vielleicht mit: "für 2 Personen?" oder auch "in einem Steinofen in Neapel", beides wären plausible Fortsetzungen. Um aus dem Rohmodell einen Assistenten zu machen, folgen daher zwei weitere Trainingsschritte, die man als Post-Training zusammenfasst.
Im ersten Schritt, dem Supervised Fine-Tuning (SFT), lernt das Modell an kuratierten Beispielen, wie eine gute Antwort auf eine Frage aussieht. Im zweiten Schritt, dem Alignment, wird das Modell durch menschliches Feedback weiter justiert: Menschliche Bewerter*innen beurteilen verschiedene Antworten und das System lernt daraus, welche bevorzugt werden. Erst danach entsteht, was wir als Chatbot erleben: ein System, das uns passende Antworten gibt, unsere Anweisungen befolgt, aber auch bestimmte Inhalte verweigert.
Auch diese Phase erzeugt spezifische Verzerrungen. Die bekannteste nennt man auf Englisch "Sycophancy" (Speichelleckerei): die Tendenz des Modells, Nutzer*innen übermäßig zu loben und ihnen recht zu geben, auch wenn sie falsch liegen. Sie entsteht, weil Menschen im Feedback-Prozess zustimmende Antworten systematisch besser bewerten als widersprechende. Das Modell lernt: Zustimmung wird belohnt. Im April 2025 musste OpenAI ein Update seines Modells GPT-4o zurücknehmen, weil es so übertrieben zustimmend geworden war, dass es Nutzer*innen in problematischen Vorhaben bestärkte. Das war kein Einzelfall: Shapira et al. (2026) weisen nach, dass die Feinabstimmung per Nutzerfeedback Zustimmungstendenzen unter bestimmten Bedingungen sogar verschärft.
Die Bewertungen, die in die Feinabstimmung einfließen, können zudem selbst verzerrt sein, etwa weil die Bewerter*innen demografisch nicht repräsentativ zusammengesetzt sind oder Selbstsicherheit im Ton als Kompetenz interpretieren. Kalai et al. zeigen, dass die üblichen Bewertungsverfahren Raten belohnen und angemessene Unsicherheit bestrafen. Das Post-Training kann deshalb Fehler aus dem Grundtraining fortschreiben und verschärfen.
Die ersten beiden Stufen betreffen das Training des Modells. Die dritte funktioniert anders: Hier durchsucht der Chatbot zum Zeitpunkt einer Anfrage externe Quellen wie Websites, Datenbanken oder Dokumente und baut die Ergebnisse in seine Antwort ein. Das Verfahren heißt Retrieval-Augmented Generation (RAG). Die Websuche, die in ChatGPT, Claude und anderen Chatbots eingebaut ist, funktioniert nach diesem Prinzip. Antworten, die auf konkreten Dokumenten basieren, sind deutlich zuverlässiger als solche, die allein aus den Trainingsdaten stammen. Die zeitliche Grenze des letzten Trainingstags wird aufgehoben, und das Modell kann auf Fachwissen zugreifen, das in seinen Trainingsdaten nicht oder nur dünn vertreten war.
Fehlerquellen bleiben dennoch bestehen, verlagern sich aber. Die Qualität der Antwort hängt nun davon ab, welche Quellen das System findet und auswählt. SEO-optimierte Inhalte, also Texte, die für die Auslese von Suchmaschinen optimiert wurden, können seriösere Quellen verdrängen. Dasselbe gilt zunehmend für GEO-optimierte Inhalte (Generative Engine Optimization), die gezielt darauf ausgerichtet sind, von KI-Systemen als Quelle bevorzugt zu werden. Das Modell kann außerdem korrekt abgerufene Informationen beim Zusammenfassen verzerren oder Aussagen verschiedener Quellen so kombinieren, dass etwas Falsches entsteht. Und wenn das Retrieval irrelevante oder widersprüchliche Dokumente liefert, halluziniert das Modell auf deren Basis weiter, nur eben mit dem Anschein, recherchiert zu haben.
Die drei Stufen erklären, warum KI-Chatbots gleichzeitig so beeindruckend und dennoch unzuverlässig sein können. Sie formulieren flüssig, weil das Grundtraining sie zu Meistern der Sprachstatistik gemacht hat. Sie klingen hilfreich, weil die Feinabstimmung sie darauf optimiert hat, Nutzer*innen zufriedenzustellen. Und sie wirken gut informiert, weil die Echtzeitrecherche ihnen Zugang zu aktuellen Quellen gibt. Dabei bleibt es wichtig, sich bewusst zu halten, dass keine dieser Stufen Richtigkeit garantiert und jede ihre eigenen Verzerrungen erzeugt.
Wer das versteht, kann KI-Outputs besser einordnen: Ist die Antwort aus dem "Allgemeinwissen" der Trainingsdaten generiert oder auf Basis einer konkreten Quelle? Klingt sie deshalb überzeugend, weil sie inhaltlich stimmt, oder weil das Modell gelernt hat, überzeugend zu klingen? Diese Fragen systematisch zu stellen, ist eine Kernkompetenz im Umgang mit KI – und eine, die sich unterrichten lässt.
Verstehen, wie KI funktioniert – und was daraus folgt: In den Workshops auf ki-lehren.de vermittle ich nicht nur Prompt-Engineering, sondern auch das Hintergrundwissen, das für eine kritische Bewertung von KI-Outputs nötig ist. Damit Sie und Ihre Schüler*innen einordnen können, wann man KI-Antworten vertrauen kann und wann nicht.
© Dr. Sven Lüder, www.ki-lehren.de
Traditionelle Prüfungsformate funktionieren nicht mehr. Vier Strategien, um weiterhin wirksam zu prüfen.
Artikel lesenÜber 60% der Lehrkräfte befürchten negative Folgen von KI für kritisches Denken. Dabei bietet KI die Chance, es systematisch zu fördern.
Artikel lesenKI verschiebt Kompetenzen in vier Dimensionen: De-Skilling, operative KI-Kompetenz, kognitive Transferfähigkeiten und veränderte Anforderungen.
Artikel lesen